
내일배움캠프에서 제공하는 데이터를 사용했습니다.
🎯 수업 목표 (오늘 “반드시” 가져갈 것)
세션 종료 후 수강생이 혼자 할 수 있어야 하는 것:
- UNION vs UNION ALL 차이를 설명하고, 목적에 맞게 선택한다. (중복 제거/유지)
- UNION이 성립하기 위한 규칙(컬럼 개수/순서, 데이터 타입, ORDER BY 위치)을 이해한다.
- JOIN을 하기 위해 공통 컬럼을 찾고, 그 컬럼이 PK인지 FK인지를 관계 관점에서 설명할 수 있다.
- INNER/LEFT/RIGHT JOIN의 결과 차이를 이해하고, “내가 보고 싶은 모수(기준 테이블)가 무엇인지”에 따라 JOIN 종류를 선택한다.
- LEFT JOIN + NULL 체크로 “~가 없는 대상”을 찾을 수 있다.
- 3개 이상 테이블 다중 JOIN에서 어떤 조인이 1:N이라서 결과가 늘어나는지를 설명하고, COUNT(DISTINCT)로 검증할 수 있다.
*테이블 파악 능력 중요!
- 추후 Today I Learne에 데이터명세서 방법론 기입!
4회차 선요약!
테이블 결합의 두 축!
- UNION: 결과를 세로로 쌓기(수직 결합)
- JOIN: 테이블을 옆으로 붙이기(수평 결합)
Part 1. UNION / UNION ALL
UNION은 여러 SELECT 결과를 하나로 합쳐서 보고 싶을 때 사용한다.
대표적인 상황은 다음과 같다.
- 11월 신청자 목록이 있고, 12월 신청자 목록이 따로 있을 때
- 웹 유입 로그와 앱 유입 로그가 따로 있고 “전체 유입”을 보고 싶을 때
- “학생 목록”과 “강사 목록”을 합쳐서 “전체 사람 목록”을 만들고 싶을 때
UNION 핵심!
열(컬럼) 수가 늘어나지 않고 행(레코드)이 늘어남
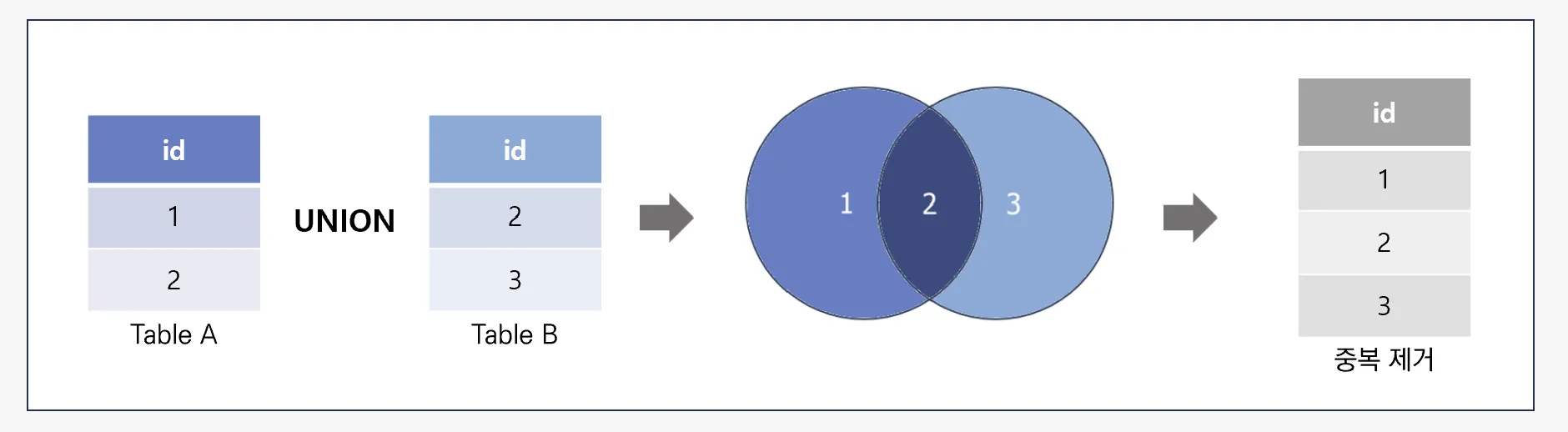
💡 UNION은 “테이블 결합”이라기보단 "결과 결합"
즉, SELECT 결과를 세로로 붙여서 하나로 만든다!
1_2) UNION vs UNION ALL
✅ 기본은 “중복 제거” (UNION = DISTINCT가 기본)
MySQL set operation은 기본적으로 중복 행을 제거 (`DISTINCT`가 기본)
✅ UNION ALL은 “중복 유지”
`ALL`을 붙이면 중복 제거를 하지 않고 그대로 다 포함
1_3) UNION 규칙 3가지
- 각 SELECT는 같은 개수의 컬럼을 반환해야 한다.
- 컬럼 수가 다르면 UNION 불가 - 같은 위치의 컬럼끼리 데이터 타입이 호환되어야 한다
(숫자 ↔ 숫자, 문자열 ↔ 문자열 등) - 결과 컬럼명은 첫 번째 SELECT 기준
컬럼명이 꼭 똑같아야 하나?
❌. 컬럼명은 달라도 되지만, UNION 결과의 컬럼명은 첫 번째 SELECT의 컬럼명(또는 별칭)을 따른다.
| UNION 기본 문법 SELECT col1, col2
FROM table_a UNION [ALL] SELECT col1, col2 FROM table_b; |
1_4) UNION에서 ORDER BY는 어디에?
UNION 결과 전체를 정렬하고 싶다면 맨 마지막에 ORDER BY를 사용한다.
Part 2. JOIN

💡 JOIN은 SQL의 꽃
UNION이 “세로로 붙이기”였다면, JOIN은 옆으로 붙이기다.
JOIN의 성패는 결국 이 3단계로 결정된다.
- 공통컬럼 찾기
- PK/FK 관계 이해
- 적절한 JOIN 방식 선택
0) 먼저 어떤 목적으로 join을 할려고 하는건가?
JOIN을 하기로 마음먹었다면, 관련된 모든 테이블의 역할과 의미를 먼저 이해해야 한다.
무작정 JOIN부터 치면 거의 100% 결과가 꼬인다. 그렇기에 JOIN 전에 스스로에게 질문해야 한다.
“최종적으로 무엇을 보고 싶은가?”
예를 들어, 최종 테이블은 학생 단위 당 결재 총액을 보고 싶다. 라고하면...
필요한 정보는
student
enrollments
payments
테이블이 필요할것이다. 그 뒤 확인을 해보자!
1) JOIN을 하기 전에 헤야할것: 공통 컬럼 찾기?
JOIN은 테이블을 연결하는 고리(키) 가 반드시 필요하다.
이 고리는 보통:
- ID 컬럼
- PK / FK 관계
JOIN은 결국 이렇게 말하는 것과 같다.
“이 행은, 저 테이블의 이 행과 같은 대상이다”
ex)
students.student_id ↔ enrollments.student_id
enrollments.enrollment_id ↔ payments.enrollment_id
2) PK / FK를 0부터 설명
✅ PK(Primary Key, 기본키)
- 한 테이블에서 각 행을 유일하게 식별하는 컬럼
- 중복되면 안 됨
- NULL이면 안 됨
👉 “이 테이블의 주민등록번호”
✅ FK(Foreign Key, 외래키)
- 다른 테이블의 PK를 참조하는 컬럼
- “이 행이 누구/무엇과 연결되는지” 알려주는 값
👉 “우리 테이블에서, 저 테이블의 누구를 가리키는가”
3) 관계(카디널리티) 감각
1:1 / 1:N 이 왜 중요한가?
JOIN이 어려운 진짜 이유는
👉 문법이 아니라, 결과 행이 늘어나는 방식 때문이다.
🔹 1:1 관계 👉 비교적 안전한 JOIN
- 한 행 ↔ 한 행
- JOIN해도 행 수가 늘어나지 않음
🔹 1:N 관계 (가장 중요) 👉 JOIN하면 행이 N배로 늘어난다
- 1쪽 테이블의 한 행
- N쪽 테이블의 여러 행과 매칭
그래서 어떻게 해야 하나? (How?)
JOIN 전에 반드시 이 순서를 거친다.
- 최종 결과의 행 단위(grain)를 먼저 선언
- N쪽 테이블은
→ JOIN 전에 집계하거나 한 행으로 줄인다 - JOIN 후 결과를 반드시 확인한다
👉 “JOIN은 붙이는 기술이 아니라, 결과를 설계하는 과정”
4) JOIN의 종류 & 기본 문법(패턴)
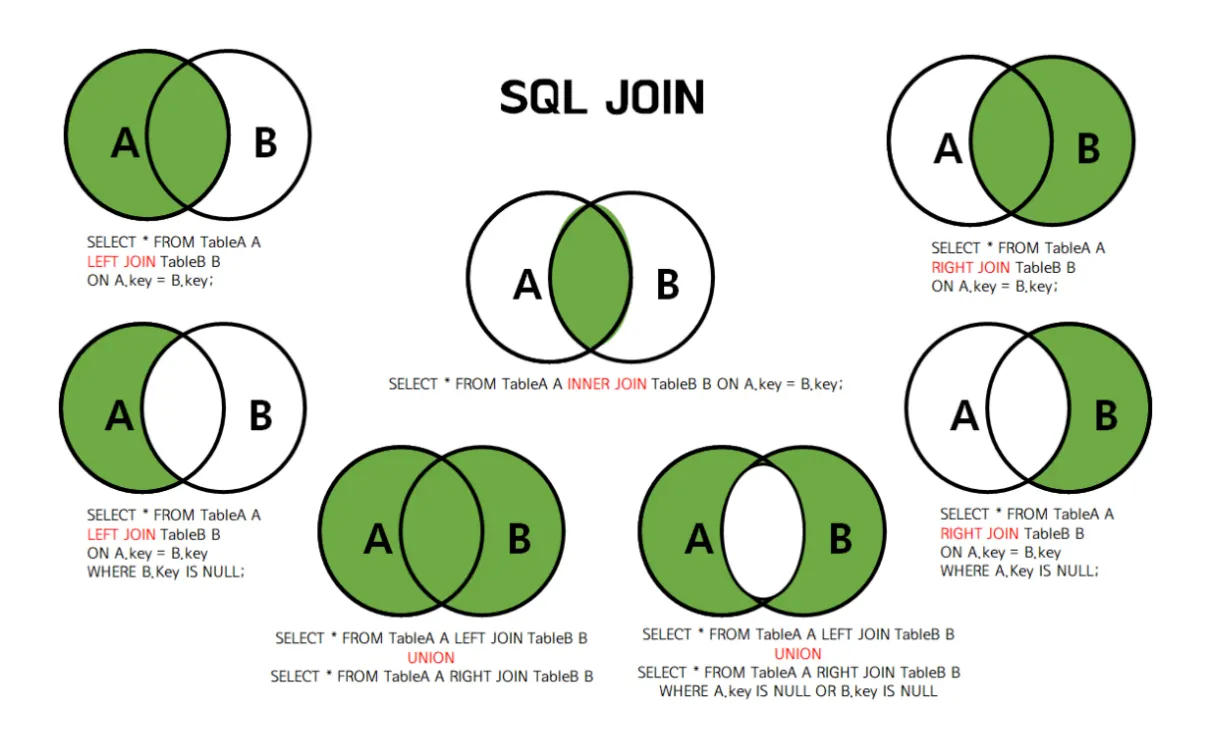
| 조인 종류 | 설명 | 반환 데이터 범위 | MySQL 지원 여부 |
| INNER JOIN (가장 많이 사용) |
두 테이블에서 일치하는 값을 가진 행만 반환 (교집합) | 두 테이블의 교집합 | 지원 |
| LEFT JOIN (가장 많이 사용) |
왼쪽 테이블의 모든 행 + 오른쪽 테이블에서 일치하는 행 반환. 일치하지 않으면 오른쪽 컬럼은 NULL | 왼쪽 전체 + 교집합 | 지원 |
| RIGHT JOIN | 오른쪽 테이블의 모든 행 + 왼쪽 테이블에서 일치하는 행 반환. 일치하지 않으면 왼쪽 컬럼은 NULL | 오른쪽 전체 + 교집합 | 지원 |
| FULL OUTER JOIN | 양쪽 테이블의 모든 행 반환 (합집합). 일치하지 않는 컬럼은 NULL로 채움 | 합집합 (교집합 + 왼쪽/오른쪽 단독 데이터) | MySQL 기본적으로 미지원 → LEFT JOIN 과 RIGHT JOIN 의 합집합으로 계산해야 함. |
| JOIN 기본문법 SELECT
a.col1, b.col2 FROM table_a AS a JOIN table_b AS b ON a.key= b.key; |
5) INNER JOIN (교집합)

✅ 언제 쓰나?
“양쪽 테이블에 모두 존재하는 데이터만 보고 싶을 때”
- 매칭 안 되는 행은 전부 제거됨
예)
- 실제로 수강신청이 있는 학생만 보고 싶다
- 주문이 있는 고객만 보고 싶다
|
SELECT
e.enrollment_id, e.enroll_date, s.student_id, s.student_name, s.region, s.segment FROM basic.enrollments AS e INNER JOIN basic.students AS s ON e.student_id= s.student_id ORDER BY e.enroll_date; |
6) LEFT JOIN (왼쪽 기준 + 매칭 없으면 NULL)

✅ 언제 쓰나?
기준(모수)을 유지하고 싶을 때
- 왼쪽 테이블은 무조건 남김
- 오른쪽에 매칭이 없으면 NULL
예)
- 전체 학생 중 수강신청 안 한 사람 찾기
- 전체 고객 대비 주문 여부 확인
| 사용 예시 SELECT
s.student_id, s.student_name, e.enrollment_id FROM basic.students AS s LEFT JOIN basic.enrollments AS e ON s.student_id = e.student_id; (null 활용) SELECT
s.student_id, s.student_name FROM basic.students AS s LEFT JOIN basic.enrollments AS e ON s.student_id= e.student_id WHERE e.enrollment_id IS NULL; |
7) RIGHT JOIN (오른쪽 기준)
MySQL 공식 문서에서도:
- RIGHT JOIN은 LEFT JOIN과 기능적으로 동일
- 이식성(portability)을 위해 LEFT JOIN 사용 권장
그래서 수업에서는:
- RIGHT JOIN은 개념만 이해
- 실제 작성은 LEFT JOIN으로 통일 추천
8) ON vs WHERE (LEFT JOIN에서 자주 터지는 함정)
MySQL 문서:
ON: 조인을 “어떻게 붙일지” 조건
WHERE: 결과에서 “어떤 행을 남길지” 필터
⚠️ 흔한 실수:
LEFT JOIN을 했는데 WHERE 때문에 INNER JOIN처럼 되어버림
오늘 JOIN 파트 회상 요약
- JOIN은 “옆으로 붙이기”
- 먼저 목적과 최종 단위(grain) 를 정해야 한다
- 공통 컬럼 + PK/FK 이해가 핵심
- 1:N 관계에서 행이 늘어나는 걸 항상 의식
- LEFT JOIN에서는 ON / WHERE 위치에 특히 주의
쿼리문 요약
|
-- 1) UNION / UNION ALL (세로 결합: 행이 늘어남)
SELECT col1, col2 FROM t1 UNION-- 기본: 중복 제거 SELECT col1, col2 FROM t2; SELECT col1, col2 FROM t1 UNION ALL-- 중복 유지 SELECT col1, col2 FROM t2; -- 2) UNION 결과 정렬은 "맨 마지막"에 SELECT col1, col2 FROM t1 UNION ALL SELECT col1, col2 FROM t2 ORDER BY col1; -- 3) INNER JOIN (가로 결합: 공통키로 매칭되는 것만) SELECT a.key, a.col A, b.col B FROM A a INNER JOIN B b ON a.key= b.key; -- 4) LEFT JOIN (왼쪽 모수 유지 + 매칭 없으면 오른쪽은 NULL) SELECT a.key, a.col A, b.col B FROM A a LEFT JOIN B b ON a.key= b.key; -- 5) "B에 없는 A" 찾기 (LEFT JOIN + NULL 체크 = anti-join) SELECT a.* FROM A a LEFT JOIN B b ON a.key= b.key WHERE b.key IS ULL; -- 6) LEFT JOIN에서 오른쪽 조건은 ON에 두기 (WHERE에 두면 모수 유실 위험) -- 모수 유지(결제 없는 신청도 남김) SELECT e.enrollment_id, p.payment_status FROM enrollments e LEFT JOIN payments p ON e.enrollment_id= p.enrollment_id AND p.payment_status='paid'; |
Part 3. 다중 JOIN + 결과 검증 루틴
복습 때 정리
Part 4. UNION vs JOIN + 함께 쓰는 패턴
복습 때 정리
'A.Today I Learne > SQL' 카테고리의 다른 글
| [TIL] SQL 라이브세션 6회차 (0) | 2025.12.31 |
|---|---|
| [TIL] SQL 라이브세션 5회차 (0) | 2025.12.30 |
| 데이터 딕셔너리에 관하여 (0) | 2025.12.29 |
| 포메팅 습관 (0) | 2025.12.28 |