
1. 데이터 딕셔너리 — 테이블을 읽는 설명서
데이터 딕셔너리는 단순한 컬럼 설명을 넘어서서 한 행(Row)이 무엇을 나타내는지와 테이블이 전체 데이터 모델에서 어떤 역할을 하는지 알려준다.
해당 개념은 저번 블로그 글에 작성되었기 때문에 참조.
2. PK (Primary Key)와 FK(Foreign Key)
PK는 테이블에서 각 행을 유일하게 구분한다.
예를 들어 users.user_id는 각각 다른 사용자 한 명을 대표한다.
PK를 알고 있으면 JOIN 조건을 세울 때 기준이 된다.
FK는 다른 테이블의 PK를 참조하는 컬럼으로, JOIN이 이루어지는 기준이 된다.
| orders.user_id는 users.user_id를 참조한다 |
이렇게 구조를 이해하면 JOIN문을 보기만 해도
무슨 일이 일어나는지 떠올릴 수 있다.
3. 관계 감각 (1:1 / 1:N) — cardinality 란?
관계 감각을 이해하는 것은 JOIN 결과를 예상하는 데 중요하다.
| 1:1 관계 — 한 행이 대응하는 한 행만 가진다 - 한 행 ↔ 한 행 - JOIN해도 행 수가 늘어나지 않음 - 결과 예측이 쉬움 |
| 1:N 관계 — 한 행이 여러 행과 대응한다 - 1쪽 테이블의 한 행 - N쪽 테이블의 여러 행과 매칭 - JOIN 순간 행이 N배로 늘어남 🚨대부분의 JOIN 사고는 여기서 발생 |
JOIN 결과에서 행 수가 갑자기 늘어나면 이 관계가 1:N이기 때문이다.
카디널리티를 케이크처럼 쉽게 먹는법
JOIN 전에 반드시 이 순서를 거친다.
- 최종 결과의 행 단위(grain)를 먼저 선언
- 학생 단위인지?
- 주문 단위인지?
- 결제 단위인지? - N쪽 테이블은
- JOIN 전에 집계하거나
- 필요한 정보만 추려서
- 한 행으로 줄인다 - JOIN 후 결과를 반드시 확인
- 행 수가 왜 늘었는지 설명 가능한가?
⭐중요⭐
JOIN은 붙이는 기술이 아니라, 결과를 설계하는 과정이다.
이 감각이 없다면 INNER / LEFT / RIGHT JOIN을 아무리 외워도 결과는 계속 틀린다.
4. UNION — 결과를 세로로 합치는 또 다른 개념
여기까지는 JOIN으로 테이블을 ‘가로로’ 연결하는 내용을 살펴봤다.
하지만 SQL에는 테이블을 ‘세로로 합치는 개념도 있다.
이것이 바로 UNION과 UNION ALL이다.
UNION과 UNION ALL의 기본 개념
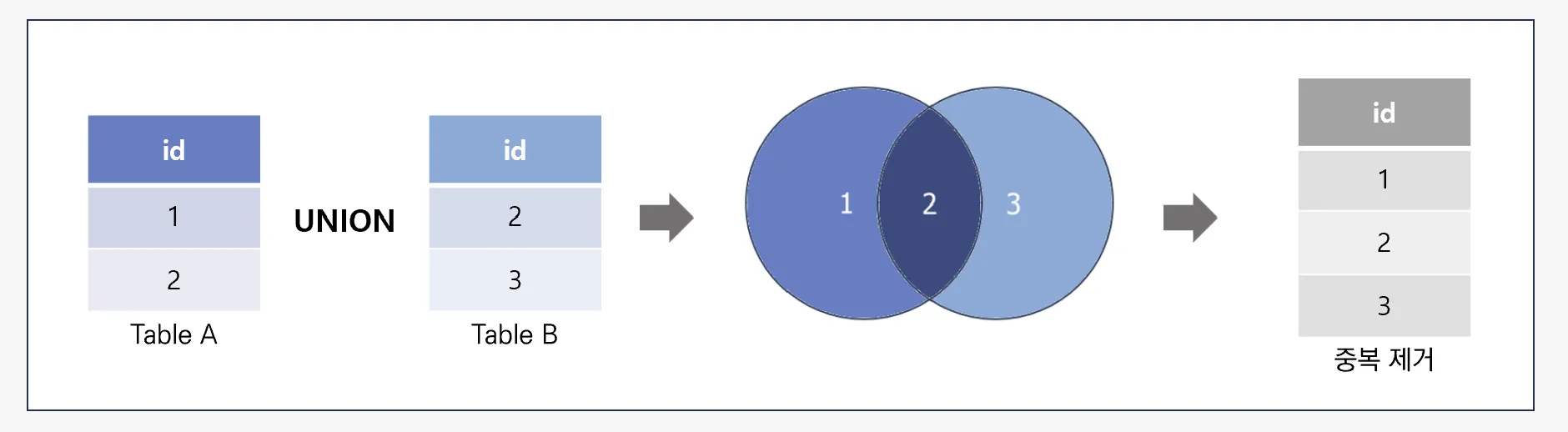
UNION은 여러 SELECT 쿼리의 결과를 하나로 합친다. 이때 UNION은 중복된 행을 제거하고 결과를 반환한다.
UNION ALL은 여러 SELECT 결과를 중복 포함해서 모두 합친다. 즉, 행이 그대로 붙는다.
기억해야 할 규칙 4가지
|
UNION 기본 사용법
수도코드
| 학생 테이블에서 A 조건 학생 리스트 학생 테이블에서 B 조건 학생 리스트 두 리스트를 세로로 합친다 중복은 제거한다 |
UNION 예시
SELECT student_id, student_name
FROM students
WHERE grade = 'A'
UNION
SELECT student_id, student_name
FROM students
WHERE major = 'Data Analytics';
UNION ALL 예시
SELECT student_id, student_name
FROM students
WHERE grade = 'A'
UNION ALL
SELECT student_id, student_name
FROM students
WHERE major = 'Data Analytics';이 경우 중복도 그대로 합쳐진다.
실행 흐름
- 첫 번째 SELECT 실행 → 결과 저장
- 두 번째 SELECT 실행 → 결과 저장
- 두 결과를 세로로 붙인다
- 중복이 있으면 제거한다 (UNION만 해당)
5. UNION과 정렬
UNION 결과에 정렬을 적용하려면
전체 결과에 대해 ORDER BY를 마지막에 한 번만 지정할 수 있다.
SELECT student_id, student_name
FROM a
UNION
SELECT student_id, student_name
FROM b
ORDER BY student_name;오늘 학습한 내용 정리
이번 챕터에서는 테이블 구조를 이해하는 기본 개념과 JOIN을 하기 전에 점검해야 할 요소들을 복습했다.
- 데이터 딕셔너리는 테이블의 의미를 설명한다 (링크 참조)
- PK와 FK는 JOIN 조건을 이해하는 기준이다
- 관계(1:1, 1:N)는 결과 행 수를 예상하게 한다
- UNION은 세로 결합 개념이다
- UNION은 중복 제거, UNION ALL은 중복 포함 결과를 반환한다
'F.SQL > SQL 기초 복습' 카테고리의 다른 글
| [SQL] 복잡한 쿼리를 다루는 방법 — 서브쿼리와 CTE (0) | 2026.01.04 |
|---|---|
| [SQL] JOIN 실전 — 테이블 연결하기 (0) | 2026.01.04 |
| [SQL] 데이터를 숫자로 요약하기 — 집계와 그룹화 (0) | 2026.01.03 |
| [SQL] 조건을 조금 더 똑똑하게 — CASE로 데이터 분류하기 (0) | 2026.01.03 |
| [SQL] 기본 흐름 — SELECT부터 정렬까지 (0) | 2026.01.03 |